
A Kubernetes deployment always creates a cluster, which consists of a set of worker machines, called nodes, that run containerized applications. Worker nodes are responsible for hosting the Pods, whereas the control plane is responsible for managing the worker nodes, as well as Pods inside a cluster. The control plane is usually configured to run multiple nodes in order to achieve greater availability. The diagram below is a representation of a Kubernetes cluster with all of its component parts.
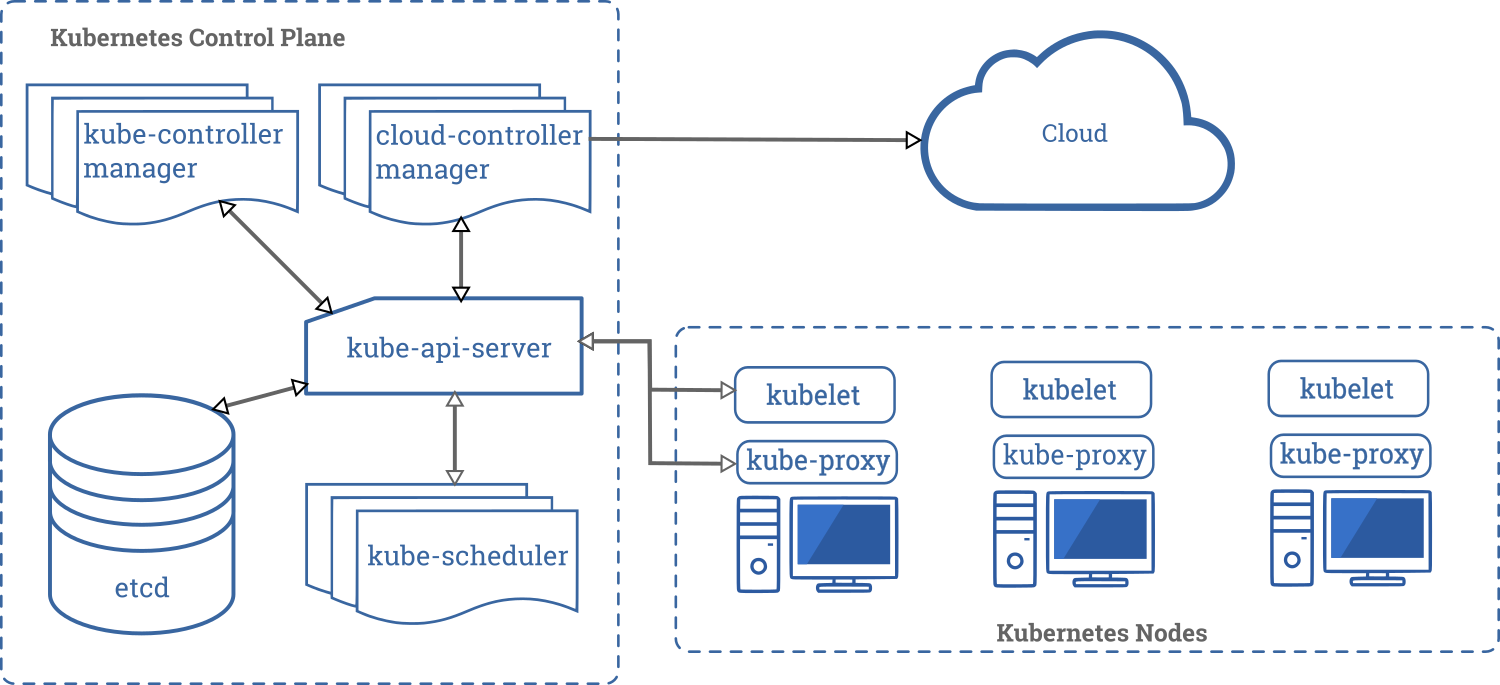
Control Plane Components
The control plane’s components monitor the cluster to ensure that the desired state is reached. It also can initiate action to directly affect the cluster (such as scheduling changes and responding to cluster events) if the actual state differs from the desired state.
-
kube-apiserver - The API server is a component of the Kubernetes control plane that exposes the Kubernetes API. The API server is the front end for the Kubernetes control plane.
-
etcd - Key-value storage used by Kubernetes to store cluster data.
-
kube-scheduler - control plane component that watches for newly created Pods with no assigned node, and selects a node for them to run on.
-
kube-controller-manager - A control plane component with the task of running controller processes, which start off as single process but are then compiled into a single binary and process to reduce complexity.
These controllers include:
- Node controller - Monitors nodes and responds if any nodes go down.
- Replication controller - Ensures that the correct number of pods is running for every replication controller object.
- Endpoints controller - Responsible for populating the Endpoints object (joins Services & Pods).
- Service Account & Token controllers - Responsible for creating default accounts and API access tokens for new namespaces.
Node Components
Node components run on every node and have different functions to maintain running Pods:
- kubelet - Agent running on each node, ensuring that containers are running in a Pod.
- kube-proxy - Network proxy running on each node, implementing a part of the Service concept and maintaining network rules.
- Container runtime - Responsible for running containers.
Add-ons
Add-ons introduce new features to clusters via the use of Kubernetes resources - a list of available add-ons can be found here.
DNS
In addition to the already existing DNS servers in an environment, a cluster DNS server is required to serve DNS records to Kubernetes services. This is automatically handled by Kubernetes.
How does DNS work inside Kubernetes?
DNS names are assigned to each service in the cluster as well as the DNS server. The Pod’s own namespace and cluster’s default domain is by default included in Pods’ search list. Consider the following example.
Let’s assume that a service named rangeforce is present in the prod namespace. Pod A is in the prod namespace and Pod B is in the dev namespace. Pod A can look up the service with a DNS query rangeforce, whereas Pod B’s DNS query will be rangeforce.prod - notice the namespace added at the end.
Most important add-ons:**
- dns: Deploy DNS. This add-on may be required by other services. So, the recommendation is to always enable it.
- dashboard: Deploy Kubernetes Dashboard, a web interface for managing applications within clusters.
- storage: Create a default storage class using the hostpath-provisioner to point to a directory on the host.
- ingress: Create an ingress controller.
- gpu: Expose GPU(s) to Kubernetes via the nvidia-docker runtime and nvidia-device-plugin-daemonset.
- istio: Deploy the core Istio services.
- registry: Deploy a docker private registry exposed on localhost, port TCP/32000. The storage add-on is activated as part of this add-on.
Kubernetes Cluster Installation
A developer or sysadmin can run K8s locally at his or her machine. It’s a good way to check out what Kubernetes has to offer. There are many different ways for users to set up their Kubernetes clusters. But as they learn new things, it’s important to stay focused on the basic things they learned as beginners.
For example, they always need to take the following things into account when choosing their setup options:
- What will the RAM utilization be?
- Can it be easily shutdown?
- Can it be easily reset?
- Can it be easily used on local machine?
One simple way is using MicroK8s which is from Canonical, the company that makes Ubuntu, but it works on any Linux distribution. MicroK8s is perfect for:
- Developer workstations
- IoT
- Edge
- CI/CD
MicroK8s provides a stand-alone K8s that is compatible with the Kubernetes managed services offerings provided by Google, Amazon and Azure.
To install it, developers and sysadmins can use sudo snap install microk8s –-classic to get the latest version of MicroK8s. They can add –channel at the end of the install command to choose a specific version, as the example below shows:
sudo snap install microk8s --classic --channel=1.18/candidate
The full list of available channels that developers can choose from is available via the snap info microk8s command.
MicroK8s comes with Kubernetes add ons built in, which developers can enable or disable at any time using the microk8s.enable and microk8s.disable commands. To see the list of all available add-ons, as well as those currently enabled, use the microk8s.status.
Integrated Commands
There are many commands that ship with MicroK8s that you should explore at your own convenience:
-
microk8s.status: Shows the status of Micro8ks and enabled add-ons. -
microk8s.enable: Enables an add-on. -
microk8s.disable: Disables an add-on. -
microk8s.kubectl: Interact with Kubernetes. -
microk8s.config: Shows the configuration file. -
microk8s.istioctl: Enables interaction with Istio services, provided that the Istio add-on is turned on. -
microk8s.inspect: Inspects the MicroK8s installation. -
microk8s.reset: Resets the infrastructure to a clean state. -
microk8s.stop: Stops all Kubernetes services. -
microk8s.start: Starts MicroK8s after it has been stopped.
MicroK8s kubectl (Kube Control)
MicroK8s has its own version of kubectl for interacting with Kubernetes. So, developers can run a range of commands to monitor and control Kubernetes.
In order to prevent conflicts with any existing installs of kubectl, MicroK8s uses a namespaced kubectl command.
To configure an alias for the kubectl command, simply append the following line to ~/.bash_aliases:
alias kubectl=microk8s.kubectl
Enabling kubectl Autocompletion
kubectl autocompletion can save you a lot of typing and can help you format your commands.
To configure kubectl bash completion, a developer needs to append to ~/.bashrc like this:
echo "source <(kubectl completion bash)" >> ~/.bashrc
Kubernetes Run, Create and Apply
Run, Create and Apply are the most common command line tools to interact with Kubernetes. But there are lots of options with Kubernetes and there are lots of ways to do the same thing. That’s because Kubernetes, unlike some of the Docker tools, comes very unopinionated and allows you to do things in various ways to fit your workflow and your team’s preference. The challenge with that is often knowing what to do. So, that requires a little more investment in learning the tools and here you will be able to achieve that.
kubectl
Kubernetes uses the kubectl command line tool, which allows developers to run commands against Kubernetes clusters.
Use the syntax below to run commands to Kubernetes:
kubectl [command] [TYPE] [NAME] [flags]
Where command, TYPE, NAME, and flags are:
-
command: Specifies the operation developers want performed on one or more resources. For example:get,describe,delete. -
TYPE: Specifies the resource type. Resource types are case-insensitive, so developers can specify plural, singular, abbreviated forms. For example:kubectl describe pod range-pod1 kubectl describe pods range-pod1 kubectl describe po range-pod1 -
NAME: Specifies the name (case-sensitive) of the resource. If no name is inserted, details for all the resources are displayed, for examplekubectl get pods.
You can perform operation on multiples resources at the same time, you can specify each resource by type and name or specify one or more files:
- To group same type resources on one line command:
Example: kubectl get pod range-pod1 range-pod2
- To specify resources types individually:
Example: kubectl get pod/range-pod1 replicationcontroller/range-rc1
- To specify with one or more files:
Example: kubectl get pods -f ./range-pod1.yaml -f ./range-pod2.yaml
-
flags: Flags are optional. You can use a-wor--watchto create a watch command.
Caution: Be aware that specified flags override default values and any corresponding environment variables.
Kubectl Quick Reference:
kubectl run – After version 1.18 only creates Pods
kubectl create – Create some resources via CLI or YAML
kubectl apply – Create/Update anything via YAML
Creating Pods - kubectl run
In March 2020, Kubernetes 1.18 came out, and the kubectl run syntax and functionality had been changed. Now kubectl run can no longer create deployments, jobs, cronjobs, services, etc. They now only create Pods.
kubectl run usage:
kubectl run NAME --image=image [--env="key=value"] [--port=port] [--dry-run=server|client] [--overrides=inline-json] [--command] -- [COMMAND] [args...]
Start an Apache Pod
kubectl run my-apache --image=httpd
Start an Apache Pod version alpine, and let the container expose port 8080
kubectl run my-apache --image=httpd:alpine --port=8080
As kubectl run command now only creates Pods, developers or sysadmins will use it mostly for some quick things or run some tests to validate your deploys.
Running a single ephemeral Pod with a bash shell:
kubectl run <pod-name> --rm -it --image <image-name> -- bash
This command will create a Pod with a bash for the developer to ping, curl or do any other kind of test. When he or she exits the bash, the Pod will be removed from their cluster.
Deleting objects - kubectl delete
kubectl delete command deletes resources by filenames, stdin (standard input), resources and names, or by resources and label selector.
Here you can have a deepest knowledge on how to add more depth on your commands.
kubectl delete usage:
kubectl delete ([-f FILENAME] | [-k DIRECTORY] | TYPE [(NAME | -l label | --all)])
Delete a Pod with a minimal delay
kubectl delete pod <pod-name> --now
Force delete a Pod
kubectl delete pod <pod-name> --force
Delete Pods and Services with same names “range” and “force”
kubectl delete pod,service range force
Delete all Pods
kubectl delete pods --all
Creating a Deployment/Objects - Kubectl create
With kubectl create command, you can create resources via CLI or YAML which gives you more flexibility.
The diagram below shows how objects are created inside a Kubernetes Cluster:
kubectl create usage:
kubectl create <objecttype> [<subtype>] <instancename>
Some object types have subtypes - additional configuration options that can be specified in the kubectl create command. The Service object has multiple subtypes, some of them being ClusterIP, LoadBalancer and NodePort.
Create a Service with subtype NodePort
kubectl create service nodeport <myservicename>
In the above example, the create service nodeport command is called a subcommand of the create service command.
Use the -h flag to find the arguments and flags supported by a subcommand:
kubectl create service nodeport -h
Create a new deployment with name “my-deploy”
kubectl create deployment my-deploy --image ubuntu
Viewing and Finding Resources
You can use the kubectl get and kubectl describe to help you view and find some valuable information about Kubernetes objects.
Here are some command that can be useful for your debugs.
List all Services in the namespace
kubectl get services
List all Pods in the namespace
kubectl get pods
List all Pods in the current namespace, with more details (like IP address)
kubectl get pods -o wide
List a particular Deployment
kubectl get deployment
Verbose output about a specific Node
kubectl describe nodes my-node
Verbose output about a specific Pod
kubectl describe pods my-pod
Conclusion
Kubernetes is the most flexible and widely adopted container orchestration system on the market today. It is a very powerful but complex system – and being forewarned is to be forearmed.
