

What is Kubernetes?
Kubernetes, also referred to as ‘K8s’, is a popular open-source container orchestration system used for automating, scaling and managing application deployment. Originally developed an internal utility by Google, it is now maintained by the Cloud Native Computing Foundation.
Kubernetes works with a wide range of container technologies, including Docker. Nowadays almost if not all cloud services have a Kubernetes-ready platform, infrastructure as a service (PaaS or IaaS), or their own Kubernetes engine, where Kubernetes can be deployed or used. Several vendors provide their own Kubernetes distributions, which go through a verification process to then become certified.
Kubernetes uses both YAML and JSON as its template language. These formats can be used interchangeably in almost all scenarios, but YAML tends to be more user-friendly and is recommended by the Kubernetes best practices.
You will see below the differences between virtualization and containerization, why you should use orchestration, differences between the two most used orchestrators in the market, and an overview of Kubernetes container abstractions and terminology.
Virtualization vs. Containerization
Virtualization provides a way to run multiple operating systems (and any number of applications) on one physical host, whereas containerization provides a way to virtualize an OS to run multiple applications in their own virtually isolated environments, without the need for a new OS for each instance.
Why Orchestration?
Kubernetes is a form of orchestration that allows users to coordinate the operation of many containers serving a workload. Docker and Docker Compose are other platform offerings and services in this space.
Some IT and DevOps teams still run containers on single nodes in AWS without orchestration. They use the features of that platform to create a similar abstraction to orchestration, such as auto-scaling groups and elastic load balancing. Other enterprise teams have such a strongly defined and well-running application that they don’t see a lot of benefits out of completely changing all that to orchestration.
Given the high adoption rate of containerization across industries, most teams will eventually use some form of container orchestration if they aren’t doing so already. For teams that are considering making this transition, or those in the early phases of making the change, it’s important to understand the available options and to choose what’s best for their environments.
One of the promised benefits of containers is that apps can be easily deployed, almost as if they were on a platform-as-a-service (PaaS) such as Heroku and Google App Engine. This tends to create new problems for small firms with thinly staffed IT and DevOps teams. Some of these new problems include finding ways to:
- Easily scale applications out/in/up/down
- Ensure containers are quickly recreated and restarted if they fail
- Automate the full container lifecycle
Here is an example. Let’s say a team has concerns about running containers on-premise, and in the Cloud, or potentially multi-cloud. They want the flexibility of a hybrid approach, so they can run containers in their data center or in a vendor cloud. Kubernetes can help with this.
Kubernetes vs. Swarm
Kubernetes and Swarm are both tools that enable automated management of containers and containerized apps and services. Both are container orchestration systems that run on a container runtime environment, such as Docker, Containerd, or CRI-O.
Both Kubernetes and Docker Swarm are supported by multiple vendors and teams of people working on the products. In general, Swarm is easier to work with. It’s more straightforward which makes it easier for teams to get started with it. Its functionality is more accessible, which makes tasks like adding nodes and managing deployments much easier. So, easy is definitely the one word that describes Swarm. Swarm is easy, but that ease of use creates constraints on what teams can do with it. Kubernetes, on the other hand, needs two words to capture its value: complexity and flexibility. Kubernetes has much more functionality, flexibility, and customization capabilities. It can solve more problems, in more ways, and also generally has wider adoption and support. But all those options make it a much more complex system to work with and master.
To break this down:
On the Swarm side
- It comes with Docker - It’s a single-vendor supported solution, meaning that the same company builds the container runtime and the orchestrator, which results in less complexity, smaller resource usage. It’s designed with the developer workflow in mind. This makes it a very good for Ops and developers to use.
- It’s easy to deploy and manage - It can easily grow to many hundreds, if not thousands of nodes without the need for a large team to manage it.
- It solves most use cases - It handles most of the common challenges of running web apps on servers, whether in the Cloud, in a data center, or even on a small devices.
- It covers all the basics - Swarm includes networking. It has an ingress. It has encryption. It has a database.
So, Swarm, solves many problems for running containers, but it doesn’t solve all the use cases for all the scenarios, where the more flexible Kubernetes can fill in the gaps.
In general, Swarm is the recommended tool when starting small, like a single person or two to three in a team. When and organization’s needs are relatively small – and so is their IT team – Swarm is likely the better orchestration choice.
On the Kubernetes side
- Clouds will deploy/manage Kubernetes for you - Clouds and vendors love to support Kubernetes. It has absolutely the broadest cloud and vendor support.
- Infrastructure vendors are making their own distributions - Companies like VMware, Red Hat do it, and even companies like Netflix are getting in on it. Those firms and many others all have their own approved version, or distribution of Kubernetes.
- Greatest flexibility - Kubernetes has the widest set of supported use cases. It provides that broad support through a dizzying array of options and choices, and even more third-party options. All those options are what makes it so complex.
- “Kubernetes First” vendor support - Due to Kubernetes dominant market share, vendors naturally tend to support Kubernetes with their product before they make the same investment for Docker’s Swarm product.
Presented below is an overview of the tooling and features of both of these platforms. Checking these features against a company’s technical requirements for their container initiatives can help teams to select the right solution to meet their needs.
Kubernetes Container Abstractions
Some of the terminologies can be confusing because they conflict with other runtimes, like Swarm, and some are just new.
Pods
The pod is the basic unit of deployment and the item most often discussed relating to Kubernetes. Technically, containers are never directly deployed inside of Kubernetes, only pods are.
Controller
Almost always, users create a controller, an object that continually monitors whether what’s going on inside of Kubernetes matches what was asked of it. It’s a different engine that has different types. You start with Deployments and ReplicaSets which you’ll be using almost exclusively. Deployments are very similar to the way Swarm does its deploys. Deployments also control your pods at lower levels. On Kubernetes. Deployment provides declarative updates, like an auto-scaling function, for pods and replicaSets.
There are different types of controllers, including third-party versions like StatefulSets (controls the deployment and scaling of a set of Pods, ensuring the ordering and uniqueness of these Pods), DaemonSets (ensures that all, or some, nodes run a copy of a Pod), and Jobs (ensures that a specified number of created Pods terminate successfully, so if you delete a Job will clean up the Pods created by this Job), CronJobs and so much more.
The flexibility of Kubernetes is that it creates these basic pod units and then allows them to be controlled in different ways. This flexibility allows teams to get really creative with their deployments.
Services
Kubernetes services, are specifically the endpoint (which in terms of Kubernetes is the list of addresses or IP and port of endpoints that implement a Service.) that you can set to a deployment or pod to create a stable access to your application so if your containers or even pod is recreated changing it’s the IP addresses you keep that stable address to access your application.
Often when you use a controller like a deployment controller to deploy out a set of replica pods, you would then set a service on that. The service just means you’re giving it a persistent endpoint in the cluster so that everything else can access that set of pods at a specific DNS name and port.
To expose services outside of a cluster, teams can use a service type called Load Balancer. This can be set this in many ways, one of which is to kubectl expose command.
An application with a service type Load Balancer set will look like this example below:
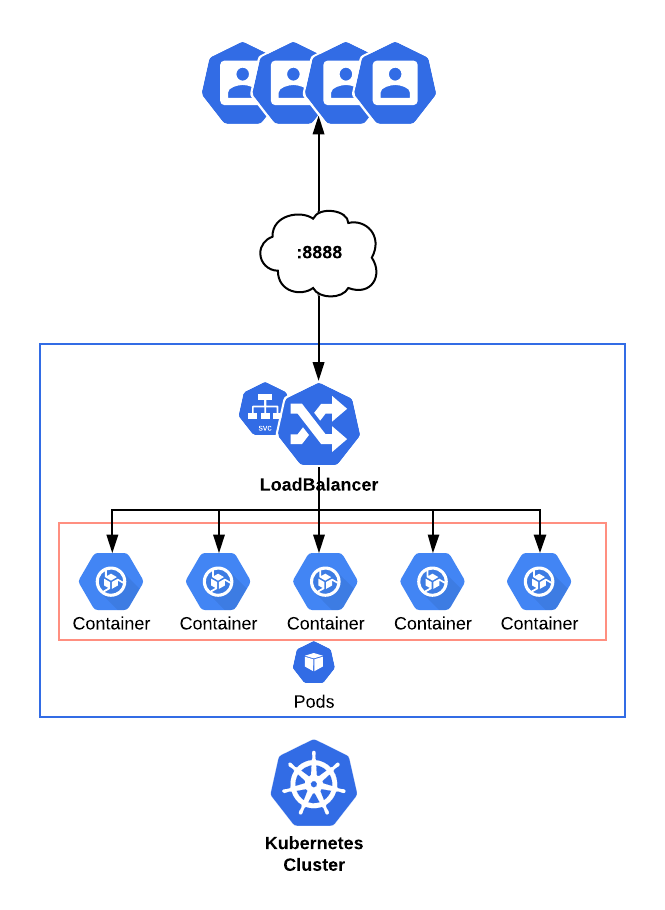
Namespaces
Kubernetes supports multiple virtual clusters running under the same physical cluster. These virtual clusters are called namespaces, offering multiple features that are especially beneficial for environments with multiple teams and/or projects. Clusters with only a few users do not benefit from namespaces. Key points regarding namespaces:
- They are a way to divide cluster resources inbetween multiple users;
- Users interacting with one namespace cannot see the contents of another namespace;
- Each Kubernetes resource can be used only in one namespace;
- Namespaces cannot be nested.
It’s important to note however that while namespaces can be used in environments with only a few users, they do not offer any significant benefits.
K8s Architecture Terminology
Just like with Swarm, the nodes are the servers that are inside of that cluster. Kubernetes refers to things as nodes as well. So, this is one area of terminology that is the same between the two systems. Everything starts at the Control plane, or master, which is in charge of running the Kubernetes cluster (as shown in the diagram below),
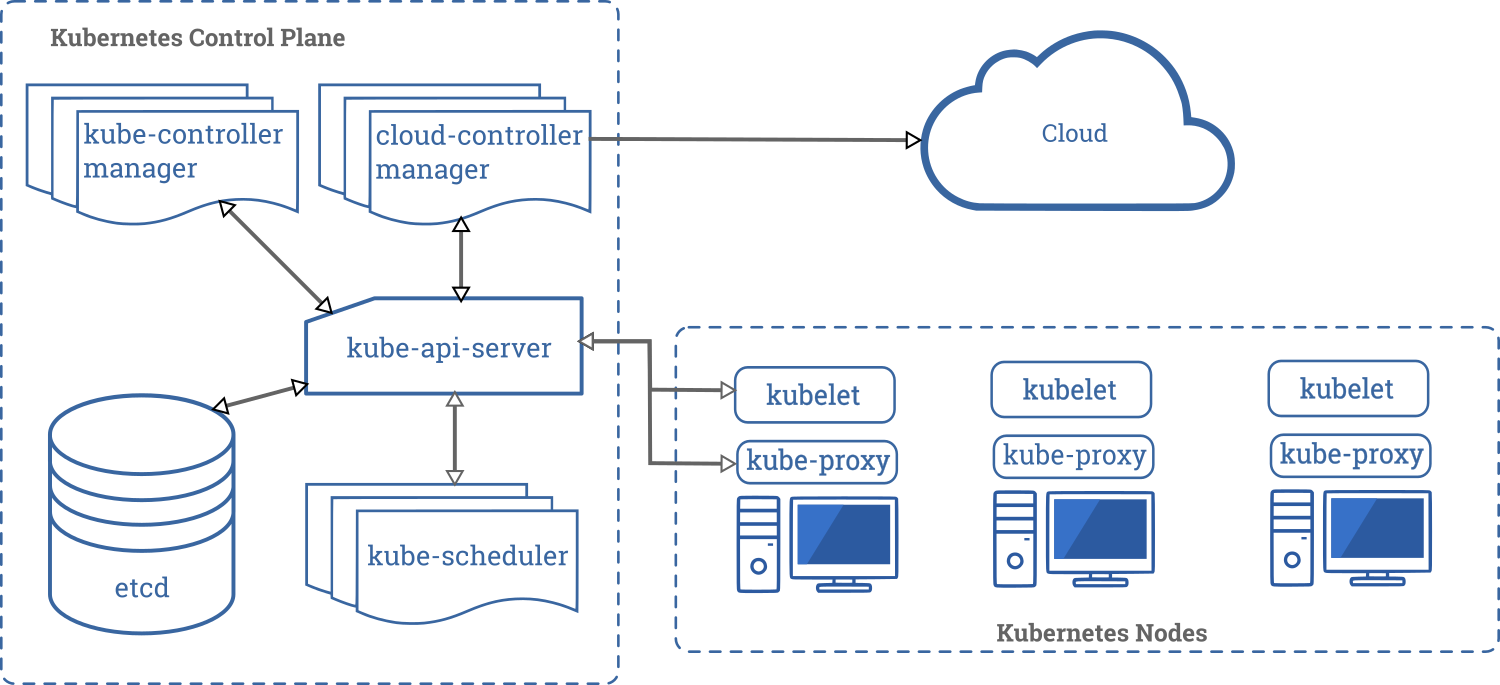
The Control Plane, sometimes called the master, is what’s in charge of the cluster.
The Control Plane, also something that is used in Swarm, is the part where the servers are running all of the programs in charge of the cluster. It’s more than one container. It’s a group of containers that run individual components. They take the Linux principle of do one thing and do it well. Essentially each one of these parts is doing just one thing but doing it well. This simplifies the design in terms of the development. But when teams have to build something like this and run it, it does make things more difficult.
As is evident in the diagram, all of these can run containers. In general, however, teams are going to keep their apps to the nodes and the Kubernetes management systems to the masters. All of these are running on top of Docker or some other container runtime like Containerd or CRI-O. Inside of each master, Kubernetes runs multiple containers to keep control of the system.
The first is etcd. Etcd is a distributed storage system for key values. etcd is a separate product and is something you can install without Kubernetes just to store configuration data. NOTE: * etcd needs an odd number of running instances for fault tolerance. Teams can start with one, but if they want true fault tolerance, they need three and so on.*
kube-apiserver is responsible for talking to the cluster and issuing orders to it.
The kube-scheduler container controls how and where containers are placed on the nodes and in pods.
kube-controller-manager is a Control Plane component with the task of running controller processes. These start off as single process but are then compiled into a single binary and process in an effort to reduce complexity. These controllers include:
- Node controller: Monitors nodes and responds if any node goes down.
- Replication controller: Ensures that the correct number of pods are running for every replication controller object.
- Endpoints controller: Responsible for populating the Endpoints object (joins Services & Pods).
- Service Account & Token controllers: Responsible for creating default accounts and API access tokens for new namespaces.
The above-mentioned controllers are responsible for looking at the state of the cluster and comparing the actual state with the desired state for which orders were given. Something to control DNS is will be needed, and it which isn’t built-in. One option is , and by default, that’s “coreDNS”, which is a flexible, extensible DNS server that which can be installed as the in-cluster DNS for pods.
Kubelet is a container that will run a small agent on each node to allow them to talk back to the Kubernetes master.
NOTE: since Docker had Swarm built-in, it didn’t really need the separate agent as it was all built into the Docker Engine.
With Kubernetes running on top of all that, it needs its own engine API that talks to the local Docker, or the local runtime, whichever one that may be.
kubectl is the command-line tool used to talk to the Kubernetes API which is the main way to communicate with the Kubernetes runtime. There are multiple tools available that can do this, but the one that comes officially from the project and that will be used most often is kubectl.
Kubernetes is designed to solve lots of problems in lots of ways. You might find yourself possibly adding more things to masters, more things to nodes, such as networking, load balancing.
Conclusion
Kubernetes is designed to solve many container-related challenges in many different ways. As a team will come to learn as they add more things to masters, and more elements to nodes, such as networking and load balancing – the sky’s the limit with Kubernetes!
Kubernetes is the most flexible and widely adopted container orchestration system on the market today, and it has attained this status for good reason. The catch is that it’s complex. To leverage its complexity to their organizations advantage, teams must be prepared to handle its complexity. In short, it’s a very powerful tool in the hands of people who know how to use it.
